Hello everyone,
We are facing a problem when trying to export our labelled text data.
In the following screenshot you can see the Labeling Interface settings:


So our goal was to label text data with these labels. We labelled all text files that we needed to but we faced the following problems when trying to export the data with the labels:
- Text data were not exported with the labels. When exporting the tasks (.json or .csv, all formats gives the same results), the annotation results are described through indices that tag the start and end indices of sentences that are labelled and not the sentences themselves. We need the labels with the sentences to be able to use the labels for our model.
So was the overview of the tasks in the LS interface:

- We tried to overcome this problem through exporting the annotations as they are with the indices so that we postprocess them through a python code that matches each text with the labels through the result indices. This did not work and the resulted matched sentences were cut off before the intended end or cut off way ahead of the beginning of the sentence. In the following there are some screenshots of a labelled text and the resulting matching attempt.

And here the resulted matching for the sentences in the previous screenshot:
“raglich ist, ob A einen Anspruch auf Herausgabe des Buchs gegen B aus § 861 I BGB hat.”: “Obersatz”,
“ies setzt voraus, dass A frühere Besitzerin des Buches war, B den Besitz am Buch durch verbotene Eigenmacht erlangt hat und der A gegenüber somit fehlerhaft besitzt (§ 858 II 1 BGB).”: “Definition”,
“udem sollte der Anspruch nicht nach § 861 II BGB ausgeschlossen bzw. nach § 864 BGB erloschen sein.”: “Definition”
As you can see, the sentences are cut off at the beginning. We thought that the problem lies at the empty lines and newline characters. We removed those from the text and matched it again but it did not work too.
We tried comparing the original text with the text processed in the LS interface and here a screenshot:
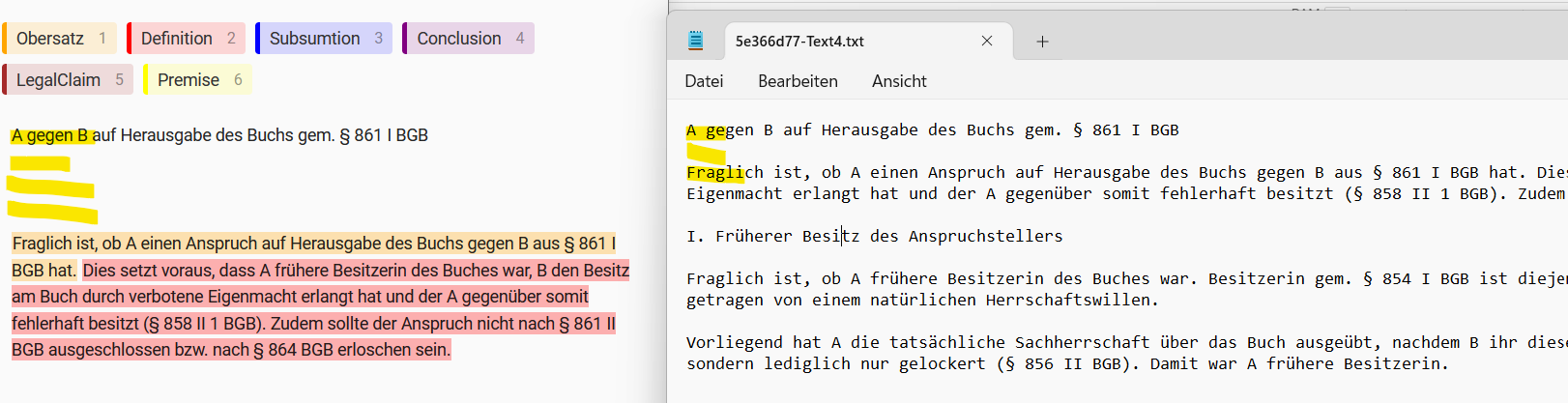
As you can see, there is a difference between both texts. It seems that LS added empty lines more than the original text contained at first. If we consider the indices tuple for the first sentence (Fraglich …) as (55, 141), it should start at 53 for the original text but LS computed it as 55.
The same counts for the other data files. The problem is, we cannot determine where exactly LS new lines added or removed. Despite downloading the text data from the upload section of LS, the matching attempts did not success.
Our questions:
- Is it possible at all, exporting the labels with the sentences directly?
- Is there a modification to the Labeling Interface that would allow this export?
- Are these problems with adding new lines to texts already known in LS?
- Is there a possibility to download these specific versions of the text data that were modified through the labeling to be downloaded? Maybe the matching processing would work then
We are out of options and stuck at this point so we are for every hint or help very thankful ![]()
Let us know if you need further input about the problem.